COLUMNA DE OPINIÓN
Solo vemos lo que el gobierno quiere mostrar. Pandemia y los datos del MINSAL
24.07.2020







Hoy nuestra principal fuente de financiamiento son nuestros socios. ¡ÚNETE a la Comunidad +CIPER!
COLUMNA DE OPINIÓN
24.07.2020




La columna explica didácticamente la forma en que el gobierno chileno entrega los datos de la pandemia y cómo eso limita las preguntas que nos podemos hacer sobre esos datos. “Solo podemos saber lo que el gobierno nos quiere mostrar” argumentan los autores. Usando el caso mexicano, indican cómo deberían presentarse los datos para que generen información útil para investigadores y ciudadanos.
En un mundo que ha sido llamado con frecuencia, y no siempre con demasiada profundidad “sociedad de la información”, una pandemia, generadora de grandes volúmenes de datos, genera una alta demanda por saber qué está pasando mediante herramientas estadísticas.
La obligación para mucha gente de quedarse en casa, junto a un ambiente mediático de que “el mundo es el teatro de operaciones” incrementa la demanda por seguir en vivo las fluctuaciones de los datos, como si fueran acciones de la bolsa. Esto que nos parece evidente, no es tal. Conocemos las oleadas de peste bubónica que asolaron la Europa medieval no por sus Big Data, sino por vívidos relatos y documentos administrativos.
En esta modalidad de entender lo que está pasando, basada en la estadística, requerimos hacer distinciones, comparaciones entre distintas situaciones, grupos, territorios. Eso es lo que llamaríamos, transitar del dato a la información. Para facilitar la comprensión de lo que sigue, precisemos que nuestro equipo trabaja con un enfoque operacional de los conceptos de dato e información. Llamamos dato a cualquier registro que permita diferenciar entre los diferentes estados que puede tener una variable (una característica) en una situación particular: hombre/mujer, positivo/negativo, pero también cantidades, como la temperatura y la edad o cualidades no binarias, como colores, o géneros.
Solamente llamaremos información a un ordenamiento que damos a los datos para responder a una “pregunta”. No se trata de cualquier orden. Para que tenga el valor de información, se requiere que resuelva una duda. Aclaremos que no necesariamente se trata de una pregunta explicitada previamente por la persona destinataria. Lo relevante es que esta “pregunta”, esta “duda resuelta” sea pertinente para quien la recibe. En esta simple, pero relevante diferenciación, subyace gran parte de la problemática ministerial.
Para entender este punto, tomemos un ejemplo: supongamos que tenemos cartografías detalladas del tráfico vehicular en Valparaíso, nuestra ciudad, y de Islamabad, ciudad pakistaní al otro lado del mundo (33° Norte en vez de Sur y 71° Este, en vez de Oeste). En ambos casos, puedo tener la misma calidad de datos, incluso puedo tenerlos ordenados y presentados de la misma manera. Sin embargo, a menos que esté en Islamabad o algo relevante de mi vida tenga que ver con los desplazamientos en dicha ciudad, ambos conjuntos de datos no tendrán el mismo valor informativo.
Sólo el dato que responde a mi pregunta es realmente información. Su valor informativo dependerá entonces de la vigencia de la pregunta, como muestran las ediciones pasadas de un diario. De hecho, en tiempos de confinamiento masivo, incluso para nosotros en Valparaíso, los datos de tránsito vehicular de nuestra propia ciudad pueden hacerse irrelevantes, si no podemos salir.
A partir de esto, surge una gran limitación del sistema chileno para contarnos lo que está pasando a partir de los datos: el gobierno no entrega los datos en forma de una base de datos que consigne anónimamente los datos relevantes de cada caso (“line list”). Una base de datos tendrá tantas líneas como casos registremos y tantas columnas como características de cada caso nos interese registrar. Así, cada línea contendrá los datos de una persona, insistimos, de forma anónima, y cada columna consignará el valor de una característica para todos y cada uno de los casos.
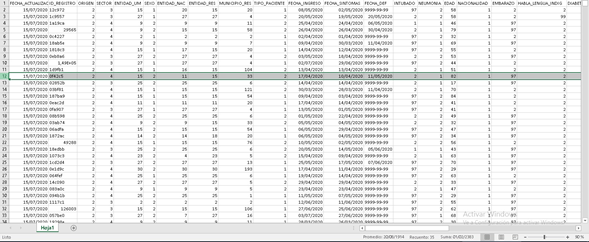
Esta imagen, de parte de la base de datos pública del Ministerio de Salud de México, obtenida el 15 de julio y que consigna más de 768.000 casos ejemplifica lo anterior. La línea en gris representa una persona de sexo femenino, que falleció a los 82 años el día 11 de mayo. Nos entrega también otra información, como la pertenencia a un grupo indígena o el momento en que inició sus síntomas.
Esta presentación permite que les preguntemos a los datos si las personas mayores de una cierta edad comienzan sus síntomas en un tiempo previo al momento de su muerte igual, mayor o menor que las personas de otras edades; podemos preguntar también si hay diferencias entre hombres y mujeres o si en esas eventuales diferencias influye o no pertenecer a un pueblo indígena.
En cambio, el ministerio de salud de Chile nos entrega resúmenes de dichos datos en forma de tablas.
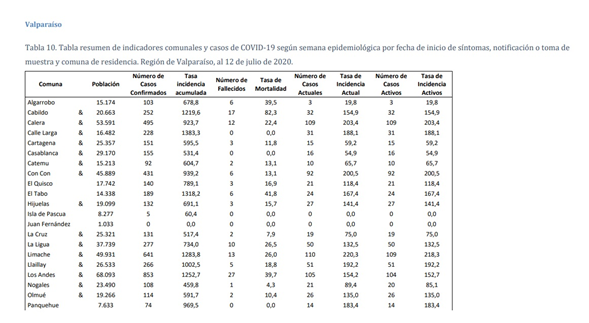
¿Qué repercusión tiene esto?
Si tenemos los datos de cada persona en forma de base de datos, podemos hacer los cruces que queramos entre las variables. Somos libres de definir la combinación de datos que responda a nuestra pregunta. En el sistema implementado por el gobierno chileno, sólo podemos saber lo que nos quiere mostrar.
El sistema de consultas no permite cruzar las variables como requiramos, sino atenernos a un libreto predefinido. Incluso el aparatoso despliegue tecnológico del ministerio de Bienes Nacionales, en forma de mapas implica una representación dirigida por el “dueño de los datos”. Introduce, de hecho, criterios tan poco relevantes por separado, como los casos por kilómetro cuadrado, al parecer, con una importancia inversamente proporcional a la experiencia epidemiológica del quien la promueve.
Aunque recientemente han aparecido dos sitios en el repositorio “Tableau Public” en que el DEIS despliega información más detallada, tampoco se trata de una base de datos que podamos explorar según nuestras inquietudes.
Supongamos que queremos saber si hay diferencias en las muertes por sobre lo esperado por causas NO COVID en diferentes comunas. Un sitio nos permitiría tener información de muertes por comuna, sexo y quinquenio de edad, pero no podríamos discriminar por diagnósticos. El otro sitio, que permitiría separar los datos por diagnóstico, no permitiría desagregarlos a nivel de comuna; solo a nivel de región.
Digamos, además que, aunque ambos sitios son administrados por el mismo DEIS, presentan datos algo distintos. Estas dos capturas de pantalla obtenidas con menos de un minuto de diferencia muestran un total de casos distinto para el mes de junio. Hacemos presente que este dato ha estado en el centro de las polémicas por la poca transparencia, por lo que esperaríamos la máxima rigurosidad.
Sitio “Hechos Vitales desde el 2000”
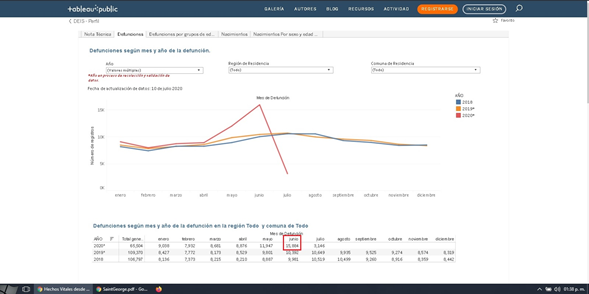
Sitio “Defunciones Semanales 1_0”
Un sitio muestra 15884 personas fallecidas y el otro 15858. Aunque la diferencia es pequeña: 26 casos, recordemos que en todo marzo el MINSAL informa 17 o 18 muertes de casos COVID confirmados y que ambos datos provienen de la misma fuente, están en el mismo repositorio y corresponden al mismo período.
Los problemas no se detienen acá. Efectivamente, podemos obtener un poco más de detalles explorando las etiquetas con datos que aparecen al posar el cursor sobre los gráficos. Para entender el trabajo que esto implica, pongamos un ejemplo:
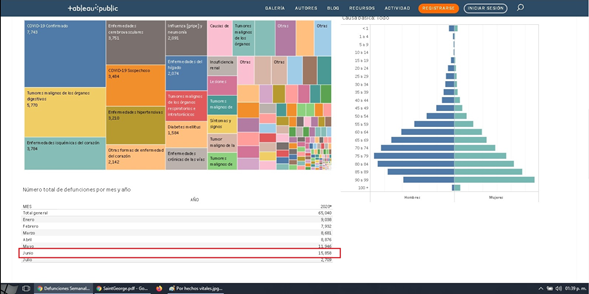
Nuestro equipo se ha interesado por entender la dinámica de fallecimientos, tanto por COVID, como por otras causas, buscando diferencias por sexo y edad. En estos casos, no basta comparar los datos actuales con los de un año anterior. Se debe establecer una tendencia de varios años, el llamado “canal endémico”. Esto exige calcular los valores normales y el rango de variación esperable para cada mes, tomando una serie de años. Para ello, recurrimos a la página Defunciones Semanales. Dado que la página sólo entrega un dato agregado a la vez, es necesario realizar una nueva consulta para cada mes.
En nuestro caso, tomamos la serie disponible completa: del 2016 hasta ahora. Es decir, debimos realizar 54 veces la consulta, mes a mes, para cada uno de los grupos diagnósticos. Esto no significa que ya tengamos los datos en la mano. Para obtener los datos por sexo y grupo de edad, debemos posar nuestro cursor sobre cada una de las líneas de la pirámide poblacional y copiar manualmente los datos para hombre y mujer de cada grupo. Son 21 grupos de edad. Es decir, para cada grupo de enfermedades: cardiovasculares, digestivas, etc., debemos pinchar ¡1.134 veces! Las barritas que representan los datos y copiarlos manualmente a un archivo Excel.
Al ser hombre/mujer, copiamos 2268 datos para cada grupo. Si quisiéramos hacerlo por regiones, deberíamos hacer ese proceso 16 veces; es decir, consultar 18.144 barritas y copiar 36.288 datos ¡para cada grupo de causas de muerte!
El sistema es, además, inestable. Quien copia los datos debe considerar que cada media hora o menos, la página volverá a su configuración por defecto, y deberá generar nuevamente la consulta.
Copia manual de datos desde sitio DEIS
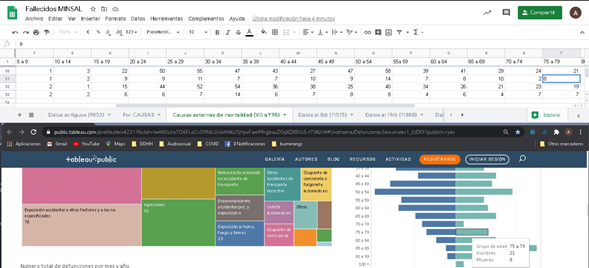
Quienes leen este artículo pueden imaginar el tiempo perdido inútilmente por equipos técnicos y la predisposición de tal sistema a los errores, simplemente porque el ministerio se niega a entregar los datos en un formato útil para quienes los exploramos. Es verdad que sistemas que despliegan tablas pre procesadas pueden acercar a personas comunes a estos temas; sin embargo, esta labor no puede justificar dejar de entregar los datos en forma que cualquiera pueda consultarlos como le parezca.
Esta tarea, de copia, digna de monjes medievales, no nos llevará a contar con una base de datos como la mexicana. Apenas tendremos tablas con datos agregados, pero al menos, con mayor detalle. Y lo que es peor, que como se ha dado en el transcurso de la pandemia, si eventualmente terminamos de hacer ese traspaso, nada asegura que al momento de hacerlo sean exactamente los mismos datos sostenidos en el tiempo.
También tendremos enormes problemas, por ejemplo, para comparar, los datos sobre edades, tan laboriosamente conseguidos. El ministerio de salud agrupa al menos de seis maneras distintas los datos de edad de las personas:
Tabla 2 de informe epidemiológico
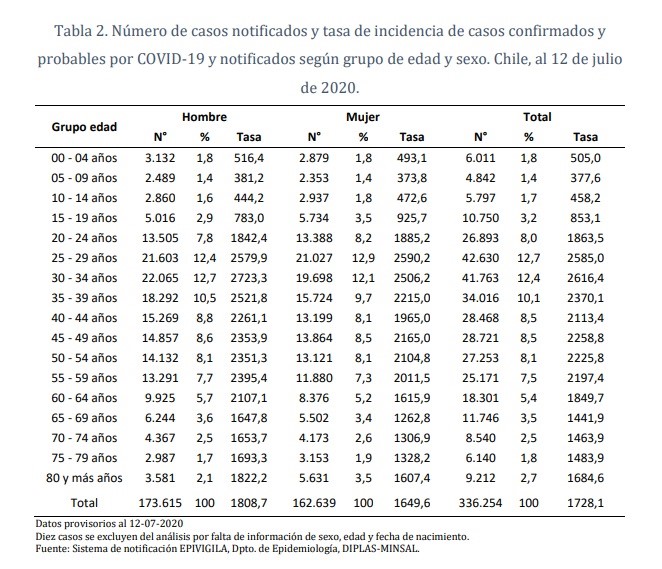
Tabla 3 de informe epidemiológico
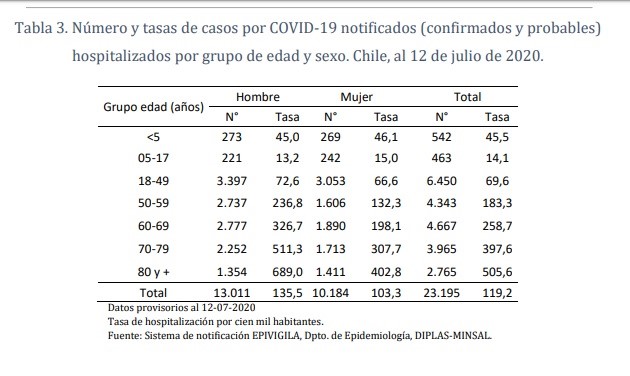
Todas las tablas hasta acá consignan sexo
Fallecidos informe diario
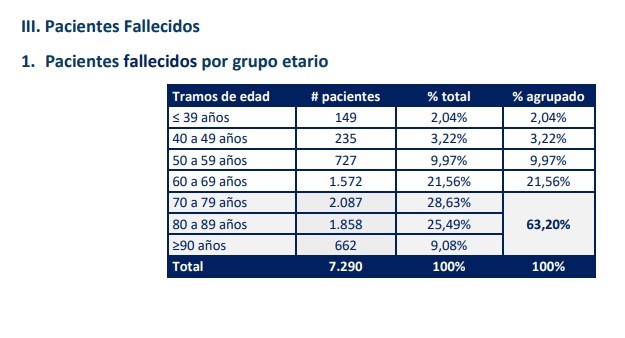
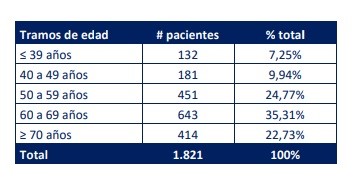
Al final, entonces, luego de toda esa lucha por construir nuestras propias interpretaciones basadas en datos, debemos reconocer (y adaptarnos a) las limitaciones de un sistema de información que no está destinado a informar, sino a transmitir una versión única y sesgada de lo que está pasando.
En este artículo pusimos como ejemplo de la política de datos del Ministerio de Salud –la que interpretamos como centrada en contar una única versión a partir de la selección de datos y de su presentación– el trabajo que tuvimos que desarrollar para obtener los datos de mortalidad por sexo/edad/causa de muerte y localización de la serie 2016 a 2020 a partir de los gráficos.
Luego de la publicación, a través de twitter la usuaria JavieraTuitera compartió un enlace a la base de datos en formato “linelist” desde el sitio del DEIS MINSAL. Se trata de una reciente fuente de datos, que sin duda constituye un avance significativo. No obstante, persiste la falta de datos en ese mismo formato, de “linelist” referentes al COVID en sí, más allá de los fallecimientos. Persiste también la presentación selectiva de datos para contar una historia exitosa. Además, sigue habiendo una diversidad de sitios donde el ministerio presenta la información, lo que hace difícil rastrear cada fuente. Esperamos que el reordenamiento del sitio del DEIS MINSAL permitirá por fin acceder a datos de mejor calidad, tratados técnicamente y disponibles en forma unificada.
Este artículo es parte del proyecto CIPER/Académico, una iniciativa de CIPER que busca ser un puente entre la academia y el debate público, cumpliendo con uno de los objetivos fundacionales que inspiran a nuestro medio.
CIPER/Académico es un espacio abierto a toda aquella investigación académica nacional e internacional que busca enriquecer la discusión sobre la realidad social y económica.
Hasta el momento, CIPER/Académico recibe aportes de cinco centros de estudios: el Centro de Estudios de Conflicto y Cohesión Social (COES), el Centro de Estudios Interculturales e Indígenas (CIIR), el Instituto Milenio Fundamentos de los Datos (IMFD), el Centro de Investigación en Comunicación, Literatura y Observación Social (CICLOS) de la Universidad Diego Portales y el Observatorio del Gasto Fiscal. Estos aportes no condicionan la libertad editorial de CIPER.









